Tutorial 4: Integrating SRT and scRNA-seq data of normal skin and psoriasis
This tutorial demonstrates SMILE’s ablility to integrate normal skin and psoriasis. The processed data can be downloaded from https://figshare.com/articles/dataset/_b_Spatial_transcriptomics_and_scRNA-seq_data_of_normal_skin_and_psoriasis_diseased_skin_b_/27997718
import warnings
warnings.filterwarnings('ignore')
from stSMILE import SMILE
import scanpy as sc
import anndata as ad
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import squidpy as sq
import scipy.sparse as sp
from scipy import sparse
from scipy.sparse import csr_matrix
import math
import torch
import torch.nn as nn
import time
import torch.nn.functional as F
from itertools import chain
from scanpy import read_10x_h5
import torch.optim as optim
import sklearn
from sklearn.neighbors import kneighbors_graph
import gudhi
import networkx as nx
from torch_geometric.nn import GCNConv
import random
import os
import json
import matplotlib.image as mpimg
Load data
section_ids = ['NS1','PP1']
adata_l = []
for i in range(len(section_ids)):
adata_i = sc.read_h5ad('/Users/lihuazhang/Documents/SMILE-main/dataset/psoriasis/'+section_ids[i]+'_ST_final.h5ad')
adata_l.append(adata_i)
# load sc data
adata0_sc = sc.read_h5ad('./dataset/psoriasis/skin_sc_final.h5ad')
adata0_sc
AnnData object with n_obs × n_vars = 578 × 2951
obs: 'orig.ident', 'nCount_RNA', 'nFeature_RNA', 'disease', 'donor', 'chemistry', 'percent.mito', 'integrated_snn_res.0.5', 'seurat_clusters', 'celltype', 'subtypes', 'subtype', 'subtype0', 'Condition', 'clusters.final', 'clusters', 'n_genes', 'leiden', 'ref'
var: 'n_cells'
uns: 'clusters_colors', 'leiden', 'log1p', 'neighbors', 'orig.ident_colors', 'pca', 'umap'
obsm: 'X_pca', 'X_umap'
varm: 'PCs'
obsp: 'adj_f', 'connectivities', 'distances'
cell_subclass = list(set(adata0_sc.obs['clusters'].tolist()))
label0_list = list(set(adata0_sc.obs['clusters'].tolist()))
# define ref as new label used
adata0_label_new = adata0_sc.obs['clusters'].tolist()
for i in range(len(label0_list)):
need_index = np.where(adata0_sc.obs['clusters'] == label0_list[i])[0]
if len(need_index):
for p in range(len(need_index)):
adata0_label_new[need_index[p]] = i
adata0_sc.obs['ref'] = pd.Series(adata0_label_new, index = adata0_sc.obs['clusters'].index)
adata0_sc.obs['Ground Truth'] = adata0_sc.obs['clusters']
adata_l.append(adata0_sc)
Run SMILE
tag_l = ['ST','ST','single cell']
in_features = len(adata_l[0].var.index)
hidden_features = 512
out_features = 50
feature_method = 'GCNConv'
alpha = 0.001
beta = 10
lamb = 1
theta = 0.001
gamma = 10 # reconstruct
spatial_regularization_strength= 0.9
lr=1e-3
subepochs=100
epochs=200
max_patience=50
min_stop=20
random_seed=2024
gpu=0
regularization_acceleration=True
edge_subset_sz=1000000
add_topology = True
add_feature = False
add_image = False
add_sc = True
multiscale = True
anchor_type = None
anchors_all = True
use_rep_anchor = 'embedding'
anchor_size=1000
iter_comb= None
edge_weights = [1,0.1,0.1]
n_clusters_l = [10]
class_rep = 'reconstruct'
adata_l = SMILE(adata_l, tag_l, section_ids, multiscale, n_clusters_l, in_features, feature_method, hidden_features, out_features, iter_comb, anchors_all, use_rep_anchor, alpha, beta, lamb, theta, gamma,edge_weights, add_topology, add_feature, add_image, add_sc, spatial_regularization_strength, lr=lr, subepochs=subepochs, epochs=epochs, class_rep = class_rep)
Pretraining to extract embeddings of spots...
epoch 0: train spatial C loss: 0.0000, train F loss: 1.3568,
epoch 10: train spatial C loss: 0.0000, train F loss: 0.6673,
epoch 20: train spatial C loss: 0.0000, train F loss: 0.5662,
epoch 30: train spatial C loss: 0.0000, train F loss: 0.5264,
epoch 40: train spatial C loss: 0.0000, train F loss: 0.5049,
epoch 50: train spatial C loss: 0.0000, train F loss: 0.4906,
epoch 60: train spatial C loss: 0.0000, train F loss: 0.4716,
epoch 70: train spatial C loss: 0.0000, train F loss: 0.4706,
epoch 80: train spatial C loss: 0.0000, train F loss: 0.4651,
epoch 90: train spatial C loss: 0.0000, train F loss: 0.4551,
Training classifier...
Training classifier...
epoch 0: overall loss: 2.3642,sc classifier loss: 1.9722,representation loss: 0.0392,within spatial regularization loss: 0.0777
epoch 10: overall loss: 0.3655,sc classifier loss: 0.1314,representation loss: 0.0234,within spatial regularization loss: 0.0981
epoch 20: overall loss: 0.2605,sc classifier loss: 0.0253,representation loss: 0.0235,within spatial regularization loss: 0.1185
epoch 30: overall loss: 0.2289,sc classifier loss: 0.0131,representation loss: 0.0216,within spatial regularization loss: 0.1142
epoch 40: overall loss: 0.2096,sc classifier loss: 0.0097,representation loss: 0.0200,within spatial regularization loss: 0.1103
epoch 50: overall loss: 0.1930,sc classifier loss: 0.0087,representation loss: 0.0184,within spatial regularization loss: 0.1016
epoch 60: overall loss: 0.1811,sc classifier loss: 0.0087,representation loss: 0.0172,within spatial regularization loss: 0.0951
epoch 70: overall loss: 0.1723,sc classifier loss: 0.0073,representation loss: 0.0165,within spatial regularization loss: 0.0924
epoch 80: overall loss: 0.1665,sc classifier loss: 0.0058,representation loss: 0.0161,within spatial regularization loss: 0.0908
epoch 90: overall loss: 0.1626,sc classifier loss: 0.0046,representation loss: 0.0158,within spatial regularization loss: 0.0910
epoch 100: overall loss: 0.1598,sc classifier loss: 0.0037,representation loss: 0.0156,within spatial regularization loss: 0.0905
epoch 110: overall loss: 0.1578,sc classifier loss: 0.0031,representation loss: 0.0155,within spatial regularization loss: 0.0898
epoch 120: overall loss: 0.1578,sc classifier loss: 0.0027,representation loss: 0.0155,within spatial regularization loss: 0.0904
epoch 130: overall loss: 0.1551,sc classifier loss: 0.0023,representation loss: 0.0153,within spatial regularization loss: 0.0893
epoch 140: overall loss: 0.1541,sc classifier loss: 0.0021,representation loss: 0.0152,within spatial regularization loss: 0.0889
epoch 150: overall loss: 0.1534,sc classifier loss: 0.0018,representation loss: 0.0151,within spatial regularization loss: 0.0889
epoch 160: overall loss: 0.1532,sc classifier loss: 0.0017,representation loss: 0.0151,within spatial regularization loss: 0.0891
epoch 170: overall loss: 0.1519,sc classifier loss: 0.0015,representation loss: 0.0150,within spatial regularization loss: 0.0880
epoch 180: overall loss: 0.1517,sc classifier loss: 0.0014,representation loss: 0.0150,within spatial regularization loss: 0.0874
epoch 190: overall loss: 0.1524,sc classifier loss: 0.0013,representation loss: 0.0151,within spatial regularization loss: 0.0890
single cell data classification: Avg Accuracy = 100.000000%
R[write to console]: __ __
____ ___ _____/ /_ _______/ /_
/ __ `__ \/ ___/ / / / / ___/ __/
/ / / / / / /__/ / /_/ (__ ) /_
/_/ /_/ /_/\___/_/\__,_/____/\__/ version 6.1.1
Type 'citation("mclust")' for citing this R package in publications.
fitting ...
|======================================================================| 100%
Identifying anchors...
Processing datasets (0, 1)
Aligning by anchors...
epoch 100: total loss:4.5174, train F loss: 2.3224, train C loss: 2.3471, train D loss: 0.2195
epoch 110: total loss:1.5619, train F loss: 1.1224, train C loss: 0.6522, train D loss: 0.0439
epoch 120: total loss:1.1480, train F loss: 0.8554, train C loss: 0.3726, train D loss: 0.0293
epoch 130: total loss:0.9204, train F loss: 0.6827, train C loss: 0.2176, train D loss: 0.0238
epoch 140: total loss:1.0647, train F loss: 0.8295, train C loss: 0.3400, train D loss: 0.0235
epoch 150: total loss:0.9950, train F loss: 0.7649, train C loss: 0.3057, train D loss: 0.0230
epoch 160: total loss:1.0203, train F loss: 0.8213, train C loss: 0.3503, train D loss: 0.0199
epoch 170: total loss:0.9430, train F loss: 0.7461, train C loss: 0.2713, train D loss: 0.0197
epoch 180: total loss:0.8780, train F loss: 0.6891, train C loss: 0.2390, train D loss: 0.0189
epoch 190: total loss:0.9583, train F loss: 0.7556, train C loss: 0.3039, train D loss: 0.0203
Updating classifier...
Training classifier...
epoch 0: overall loss: 2.6186,sc classifier loss: 2.2072,representation loss: 0.0411,within spatial regularization loss: 0.0887
epoch 10: overall loss: 0.4727,sc classifier loss: 0.2321,representation loss: 0.0241,within spatial regularization loss: 0.1260
epoch 20: overall loss: 0.3169,sc classifier loss: 0.0786,representation loss: 0.0238,within spatial regularization loss: 0.1492
epoch 30: overall loss: 0.2753,sc classifier loss: 0.0478,representation loss: 0.0227,within spatial regularization loss: 0.1543
epoch 40: overall loss: 0.2532,sc classifier loss: 0.0343,representation loss: 0.0219,within spatial regularization loss: 0.1524
epoch 50: overall loss: 0.2386,sc classifier loss: 0.0272,representation loss: 0.0211,within spatial regularization loss: 0.1486
epoch 60: overall loss: 0.2277,sc classifier loss: 0.0217,representation loss: 0.0206,within spatial regularization loss: 0.1455
epoch 70: overall loss: 0.2266,sc classifier loss: 0.0200,representation loss: 0.0206,within spatial regularization loss: 0.1445
epoch 80: overall loss: 0.2125,sc classifier loss: 0.0156,representation loss: 0.0197,within spatial regularization loss: 0.1414
epoch 90: overall loss: 0.2087,sc classifier loss: 0.0141,representation loss: 0.0195,within spatial regularization loss: 0.1380
epoch 100: overall loss: 0.2025,sc classifier loss: 0.0125,representation loss: 0.0190,within spatial regularization loss: 0.1358
epoch 110: overall loss: 0.1984,sc classifier loss: 0.0111,representation loss: 0.0187,within spatial regularization loss: 0.1346
epoch 120: overall loss: 0.1945,sc classifier loss: 0.0096,representation loss: 0.0185,within spatial regularization loss: 0.1326
epoch 130: overall loss: 0.1914,sc classifier loss: 0.0085,representation loss: 0.0183,within spatial regularization loss: 0.1310
epoch 140: overall loss: 0.1886,sc classifier loss: 0.0076,representation loss: 0.0181,within spatial regularization loss: 0.1296
epoch 150: overall loss: 0.1870,sc classifier loss: 0.0068,representation loss: 0.0180,within spatial regularization loss: 0.1279
epoch 160: overall loss: 0.1844,sc classifier loss: 0.0062,representation loss: 0.0178,within spatial regularization loss: 0.1275
epoch 170: overall loss: 0.1827,sc classifier loss: 0.0056,representation loss: 0.0177,within spatial regularization loss: 0.1260
epoch 180: overall loss: 0.1820,sc classifier loss: 0.0052,representation loss: 0.0177,within spatial regularization loss: 0.1259
epoch 190: overall loss: 0.1814,sc classifier loss: 0.0048,representation loss: 0.0177,within spatial regularization loss: 0.1236
single cell data classification: Avg Accuracy = 100.000000%
adata_concat_st = ad.concat(adata_l[0:len(section_ids)], label="slice_name", keys=section_ids)
sc.tl.pca(adata_concat_st)
adata_concat_st.obsm['X_pca_old'] = adata_concat_st.obsm['X_pca'].copy()
adata_concat_st.obsm['X_pca'] = adata_concat_st.obsm['embedding'].copy()
sc.pp.neighbors(adata_concat_st)
sc.tl.umap(adata_concat_st)
sc.tl.leiden(adata_concat_st, random_state=666, key_added="leiden", resolution=0.5)
len(list(set(adata_concat_st.obs['leiden'].tolist())))
10
Results and visualizations
from stSMILE import analysis
analysis.mclust_R(adata_concat_st, num_cluster=10, used_obsm="embedding")
fitting ...
|======================================================================| 100%
AnnData object with n_obs × n_vars = 1717 × 2951
obs: 'in_tissue', 'array_row', 'array_col', 'n_genes', 'pd_cluster', 'slice_name', 'leiden', 'mclust'
uns: 'pca', 'neighbors', 'umap', 'leiden'
obsm: 'spatial', 'embedding', 'hidden_spatial', 'reconstruct', 'deconvolution', 'X_pca', 'X_pca_old', 'X_umap'
varm: 'PCs'
obsp: 'distances', 'connectivities'
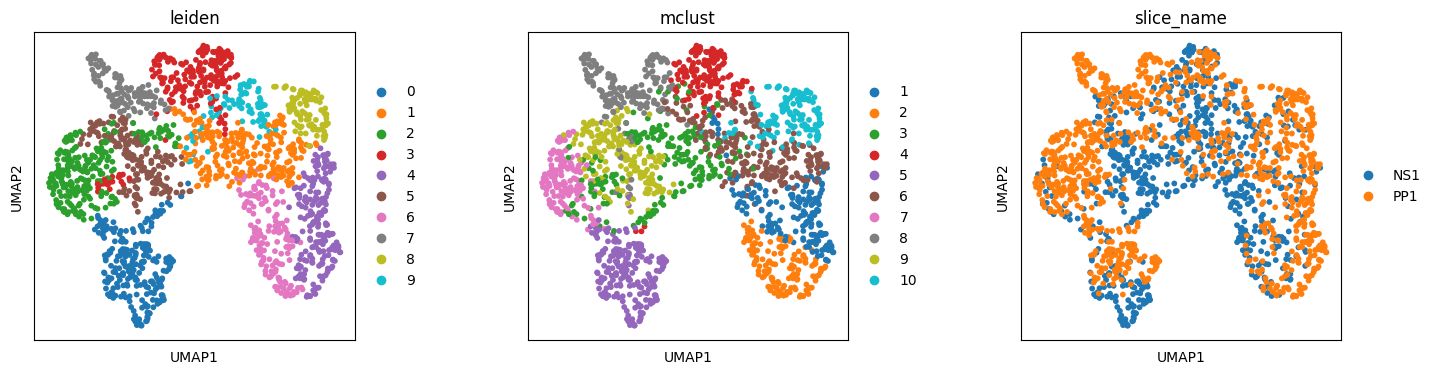
plt.rcParams["figure.figsize"] = (4, 4)
sc.pl.umap(adata_concat_st,color=["leiden","mclust",'slice_name'], wspace=0.4, save = 'Skin_umap_cluster_SMILE.pdf')
WARNING: saving figure to file figures/umapSkin_umap_cluster_SMILE.pdf
# split to each data
Batch_list = []
for section_id in section_ids:
Batch_list.append(adata_concat_st[adata_concat_st.obs['slice_name'] == section_id])
import matplotlib.pyplot as plt
spot_size = 20
title_size = 12
fig, ax = plt.subplots(1, 2, figsize=(10, 5), gridspec_kw={'wspace': 0.05, 'hspace': 0.1})
_sc_0 = sc.pl.spatial(Batch_list[0], img_key=None, color=['mclust'], title=[''],
legend_loc=None, legend_fontsize=12, show=False, ax=ax[0], frameon=False,
spot_size=spot_size)
#_sc_0[0].set_title("ARI=" + str(ARI_list[0]), size=title_size)
_sc_1 = sc.pl.spatial(Batch_list[1], img_key=None, color=['mclust'], title=[''],
legend_loc='right margin', legend_fontsize=12, show=False, ax=ax[1], frameon=False,
spot_size=spot_size)
#_sc_1[0].set_title("ARI=" + str(ARI_list[1]), size=title_size)
plt.savefig("Skin_SMILE_mclust.pdf")
plt.show()

# write out the result
for i in range(len(section_ids)):
adata_i = adata_l[i].copy()
ot_i = adata_i.uns['deconvolution']
ot_i.to_csv('Skin_SMILE_'+ section_ids[i]+'.csv', sep='\t')
del adata_i.uns['deconvolution']
del adata_i.uns['deconvolution_pre']
adata_i.write('Skin_SMILE_'+ section_ids[i]+'_ST.h5ad')
del adata_i
adata_i = adata_l[len(section_ids)].copy()
adata_i.write('Skin_SMILE_'+ section_ids[i]+'_sc.h5ad')